Mapping the “memory loss” of disinformation in fact-checks: the challenge of preserving disinformation traces
According to a survey conducted by vera.ai, archiving appearances of disinformation is one of the most cumbersome tasks fact-checkers perform, mainly due to anti-scraping measures taken by Facebook, Instagram, TikTok, and other platforms. This may result in less documented fact-checks, fewer appearances, and less evidence of disinformation traces. The platforms - as well as their users - also at times remove fact-checked or debunked posts, or make them private afterwards.
Therefore, many links to disinformation content disappear, either erased by platforms or their end-users, or kept within private groups after debunks. This has adverse effects on ‘fact-checking memory’ and respective narratives. It also poses challenges for social scientists to evaluate the scope of disinformation on the various platforms.
Identifying the archiving practices and the “memory loss” for links from the war in Ukraine dataset
At the Digital Methods Winter School and Data Sprint 2023 at the University of Amsterdam, we researched ways to map the fact-checking “memory loss”. We used the “War in Ukraine” fact-check dataset published by the European Digital Media Observatory (EDMO) as an entry point.
Within the 1,991 fact-checking articles, we collected 41,758 links of which 6,002 are archived web pages. We identified missing, altered, non-functioning published contents or corresponding archive material to assess what has been correctly preserved.
Multiple fact-checking organizations have contributed to archiving links. We identified the organizations, their contribution count, and their country in Figure 1. and 2. We also looked at the evolution of the publications over time by mapping them with the events of the War in Ukraine in Figure 3.



A few dominant web archives
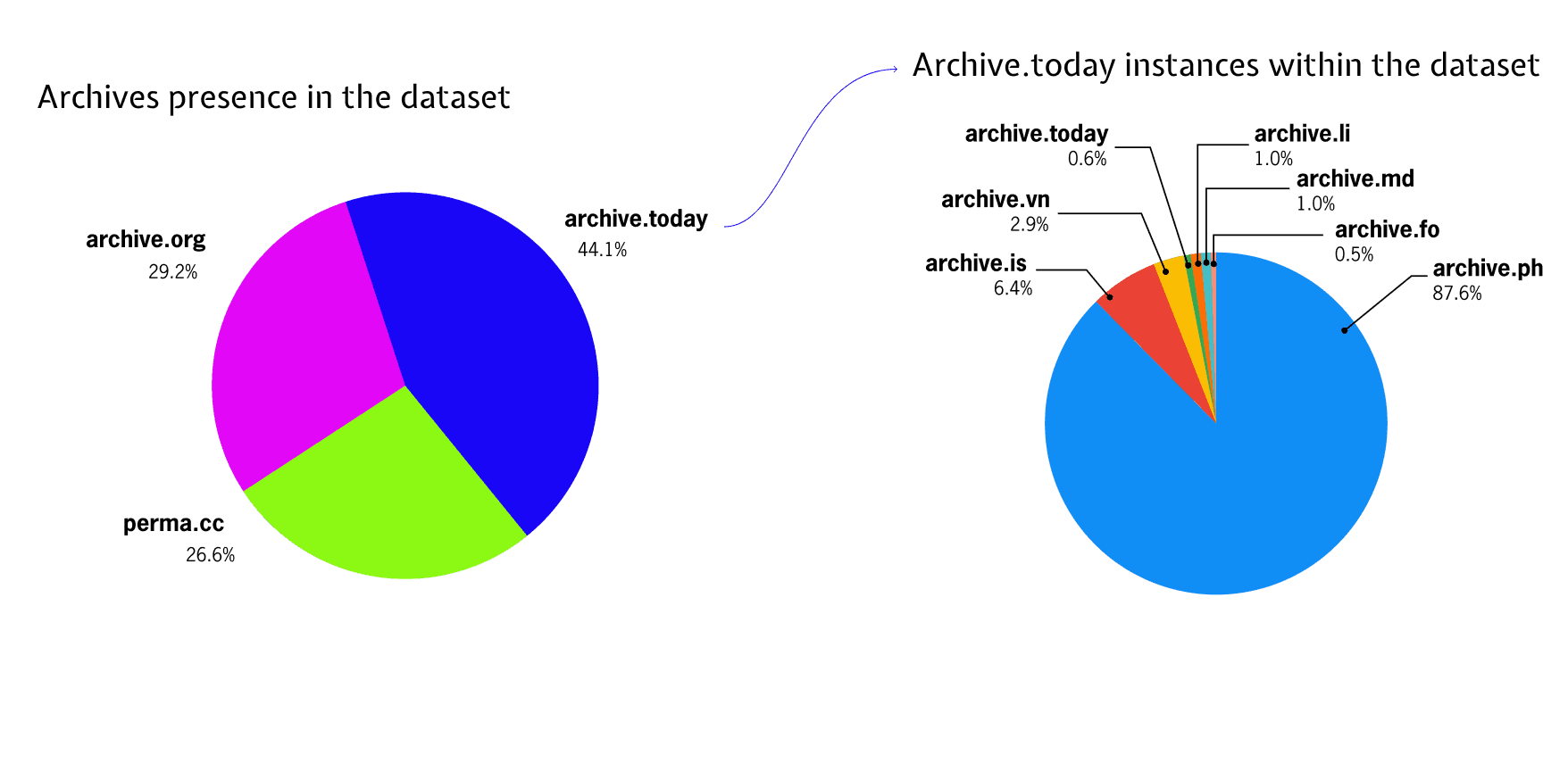
Fact-checkers use multiple hosting websites. The usage repartition of the domains in Figure 4. highlights that organizations captured material for archiving using 3 major hosting domains: archive.today (44.1%), archive.org (29.2%), and perma.cc (26.6%) (Figure 4.).
Archive.today relies on advertising, perma.cc is a freemium and commercial service built at Harvard University and the US Wayback Machine / Internet Archive is still a free-access web archive at the time of writing.
Archive.today and its various mirror sites appear as the most used open-access archiving services. Archive.ph, in turn, is the most prominent one within the Archive.today mirrors.
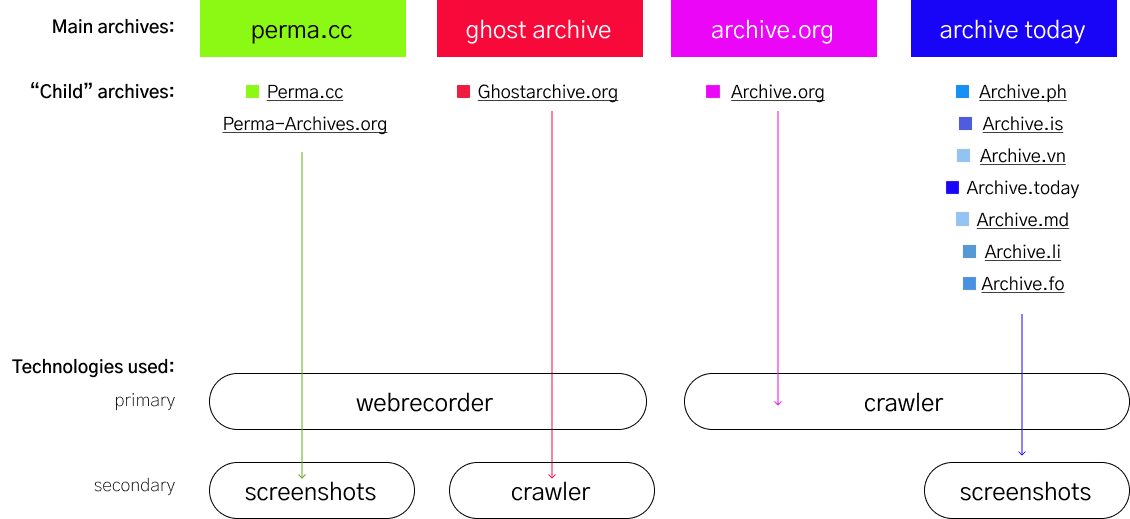
The archiving domains have different technologies to enable capturing content (Figure 5.). Often, there are problems when trying to capture and archive video content.
Archive.today can archive up to 50MB of a webpage, which is why some archived links have missing elements. In all the links we checked, Archive.today does not allow to play any videos across the different platforms. Since the service uses a crawler, we could not interact with the content.
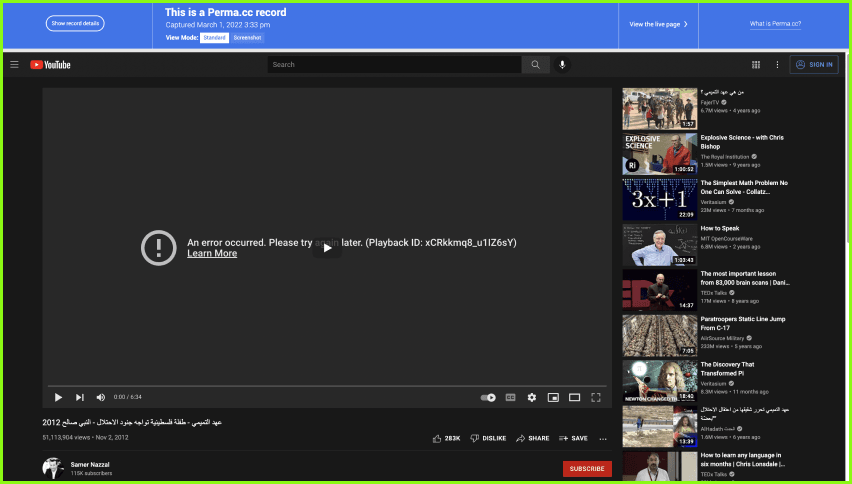
Although perma.cc uses Webrecorder, a service that has the capability to archive media contents like videos, we still found about one third of the perma.cc links with unplayable videos, as depicted in Figure 6.
In some instances, Facebook still requires logging in to view the archived content: the archive captures an error message or a log-in screen instead of the content to record. This subjects the archives to the platform’s governance of access.
Mapping the “memory loss”
To know if a piece of content is correctly archived, we have attempted to use multiple Digital Methods (Rogers, 2013).
First, we analyzed archive links and HTTP response status codes with web mining tools Minet (Plique et al., 2019) and Hyphe (Jacomy et al., 2016). HTTP Success codes for archive links do not always translate into content availability, with videos missing or unplayable in the archives.
Then, we designed a new extraction process relying on Webrecorder and Machine Learning-based OCR to identify the error messages of the web archive pages. With this new method, we found that at least 15% of the archived content links in our dataset are badly archived, displaying errors or partial archives. Moreover, the measured “memory loss” is even more critical as unplayable videos are quite difficult to identify through the aforementioned method.
In a manual analysis carried out by UvA students of a random sample size of 100 links within our dataset, the overall rate of errors was up to 43%, with the majority of the errors being unplayable videos.
Another automated exploration on a sub-corpus of 1,391 Facebook links not archived but retrieved from the same dataset shows that 23% of the content is not available anymore.
What we learned
Three main archive services (archive.today and its satellite; archive.org and perma.cc) are currently dominating the field. Their use by fact-checking organizations rely often on their ability to archive content from platforms and especially from Facebook, due to anti-bots and anti-scraping measures.
While platform's pages seem to remain accessible (HTTP 200 status), we found that a significant number of them display archived warnings (of which a sample is available with screenshots in the project poster below) illustrating different types of archiving issues from login barriers to unplayable video content.
To understand the scope of the “memory loss” and the complications faced when archiving content, we plan to improve our solution to tackle challenges faced when collecting and creating datasets of archived links. We will also extend this study to more datasets by reusing the methodology elaborated during the Winter School data sprint.

Resources
European Digital Media Observatory. (n.d.). War in Ukraine: The fact-checked disinformation detected in the EU. https://edmo.eu/war-in-ukraine-the-fact-checked-disinformation-detected-in-the-eu/#
Rogers, R. (2013) Digital Methods. MIT Press
Datamining and crawling tools used
Plique, G., Breteau, P., Farjas, J., Théro, H., Descamps, J., Pellé, A., & Miguel, L. (2019, October 14). Minet, a webmining CLI tool & library for python. Zenodo. http://doi.org/10.5281/zenodo.4564399
Jacomy, M., Girard, P., Ooghe-Tabanou, B., & Venturini, T. (2016, March). Hyphe, a curation-oriented approach to web crawling for the social sciences. In Tenth International AAAI Conference on Web and Social Media.
Archiving tools and websites
Webrecorder (suite of applications to record web archives)
archive.org (Internet Archive or Wayback Machine)
Author(s): Valentin Porcellini (AFP) - based on the contributions and work of the entire team, namely Denis Teyssou, Kalina Bontcheva, Bertrand Goupil, Valentin Porcellini, Muneerah Patel, Iknoor Singh, Ian Roberts, Mark Greenwood, Yan Cong, Ziwei Zhang, Nadia Murady, Sayat Rahman Chowdhury, Ángeles Briones
