Recent advances in AI could empower researchers and fact-checkers to monitor misleading political narratives and harness platform data to study their influence
While posing new challenges for those combating disinformation, Large Language Models (LLMs) also present the promise of substantial improvements in our ability to comprehend extensive datasets of social media posts. To evaluate these promises in a real-world scenario, the University of Urbino team involved in vera:ai designed and tested a novel methodological approach. This approach aims to identify, categorize, and label similar political narratives, thereby measuring their exposure on social media. Initially, this innovative technique was tested on political links shared on Facebook in the lead-up to two Italian general elections. This research was conducted within the framework of WP4 in vera:ai, with a focus on modeling disinformation campaigns and assessing their impact.
Context
The rise of social media has increased citizen news involvement, yet heightened misinformation risks. Despite these risks, studies aiming to estimate false news prevalence and understanding its targets have faced methodological challenges due to various limitations posed by the techniques to measure exposure.
Over the years, researchers used different techniques to measure political information exposure, surveys, tracking tools, and media diaries, each with its own specific limitations.
Research based on platform-provided data could overcome these limitations, but these datasets are often difficult or impossible to access. One of these datasets is available for researchers, namely Meta's URL Shares Dataset (USD).
The USD is an anonymized dataset that allows researchers to study user interaction with external web links on Facebook. The utilized version, version 10, covers user interactions from 46 countries, including more than 68 million links shared on Facebook between January 1, 2017, and October 31, 2022. To protect user privacy, only URLs publicly shared by over 100 users, with Laplace random noise added, are included. The data includes various information about the links, including URL, parent domain, the date it was first shared, country code of the most frequent sharers, and rating by a third-party fact-checker if available.
Methodology
In light of these considerations, we designed an approach to analyze political URLs shared on Meta's social media platforms to surface the main narratives, eventually problematic, and measure the exposure to these narratives.
Using Meta's USD, we decided to test this methodological approach on the Italian Facebook users in the 2018 and 2022 pre-election periods.
After the first phase of testing, we developed a binary classifier fine-tuning the OpenAI curie model achieving an excellent grade of precision (0.911, recall = 0.883, F1 score = 0.897).
Then, we decided to focus on political URLs and aggregate this news by similar narratives using a k-means clustering algorithm applied to document embeddings of 27,487 URLs in 2018 and 8,308 URLs in 2022. We identified 27 topical clusters in 2018 and 24 in 2022.
Finally, we employed the OpenAI gpt-3.5-turbo model to automatically label each cluster by feeding the model with a sample of links in each cluster. Interactive visualization of the clusters for 2018 and 2022 are available (see links).
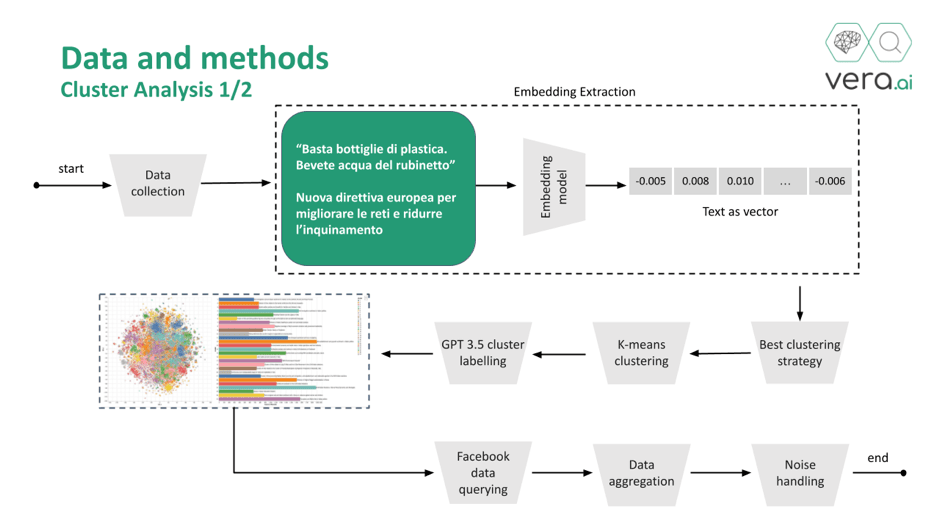
To count the number of Italian users (broken down by age groups) who viewed each URL, we queried Meta's USD using the unique identifiers of all political URLs classified in each cluster. These values were then aggregated by clusters, taking into account the effect of the noise. This process provided insights into how different age groups interacted with political content during the election periods
Preliminary findings
Our analysis quantified a substantial reduction in the circulation and overall exposure of political links among Italian users between 2018 and 2022, with the dataset's number of URLs, political URLs, and cumulative views declining by a factor of three.
We also observed a significant shift towards an older demographic within the platform's user base, with over half of all activity being attributed to users over 55.
In terms of topics, stories related to the economy accounted for a third of all views in 2022, while immigration was the most prevalent topic in 2018.
Despite these differences, several recurring themes and a consistent anti-establishment sentiment characterized both campaigns.
Our results also indicated that older users were exposed to hyper-partisan sources more frequently than other age groups.
*****
For more: the methodological approach and findings outlined above have been presented in more detail in a paper submitted to and published on the occasion of the annual conference of the Italian Association of Political Communication, held at the University of Torino from 8 - 10 June 2023. Title: "Beyond digital political communication: platforms, algorithms and automation" (authors: Fabio Giglietto*, Giada Marino*, Roberto Mincigrucci*, Nicola Righetti**, Luca Rossi***, Anna Stanziano*, Massimo Terenzi* – *University of Urbino; **University of Vienna; ***IT University of Copenhagen).
Authors of this post: Giada Marino and Fabio Giglietto (University of Urbino)
Editor: Jochen Spangenberg (DW)
