Editor‘s note: This is another post coming out of the 2023 Winter School and Data Sprint, organised by the University of Amsterdam’s Digital Methods Initiative. Here, a team coordinated by vera.ai partner Ontotext report about and provide insights into their project that dealt with ways of modeling the spread of disinformation and identifying components and connections between various instances.
Uncovering the Underlying Model of Cross-Border Disinformation and Teaching Technologies to Identify it in its Early Stages
Guiding question of the work carried out: How to model the spread of disinformation by identifying its components and the connection between various instances?
Disinformation content spreading between countries and cultures frequently reuses bits of content. This can take the form of especially convincing stories, affecting images or videos, appealing to traditions, fears of new technologies, and so on. As and while these bits of disinformation travel around the world, there is often a clear connection between them in the form of this reused content. However, an adaptation to the local context also often takes place with the aim to make the content resonate with a particular audience. While this kind of content reuse is obvious when seen, it is not obvious how to formally present it or demonstrate its effects on scale (i.e. over tens of thousands of instances of disinformation).
At the "Digital Methods Winter School and Data Sprint 2023" held in Amsterdam on 9-13 January, Ontotext proposed a project aimed to engage the participants to provide an analysis on how to identify the different elements in the spread of disinformation, and how to reduce disinformation dissemination through insights and tools.
The methodologies applied and the conclusions drawn in the course of this collaborative work are set to contribute to Ontotext’s and other partners’ efforts to model disinformation campaigns within the vera.ai project. As part of its tasks in vera.ai, Ontotext is also expanding the multilingual coverage of the so-called ‘Database of Known Fakes (DBKF)’, first prototyped in the WeVerify project, to include debunks in Central and Eastern European languages, as well as other languages of the European Union.
Therefore, language was an integral part of this particular 2023 Winter School project. Participants conducted research and identified debunks in their native languages, which were then translated into English to be shared with their team.
The working process
The Ontotext team was thrilled to facilitate a week-long research project at the DMI Winter School 2023. The overall topic of the particular workshop project was Modeling and Tracking Disinformation Spread. It brought together a group of 15 participants, the maximum allowed for a team, to collaborate and conduct research in a selected field.
Firstly, the participants identified 20 claims of disinformation spread including their reused content, novel/adaptive content and connections between various instances.
Secondly, they collected data on these instances using tools for disinformation detection and debunking including the Database of Known Fakes (Multilingual, Faceted, Multimodal Search), Google Fact Check Explorer, Social Network Search Tools, Reverse Image Search (Google Lens), Reverse Video Search, the Image Verification Assistant, and the Deepfake Detection of Facial Manipulation tool.
Thirdly, the participants analyzed the data and identified the common patterns between cases. They created a scheme to visually represent the model.
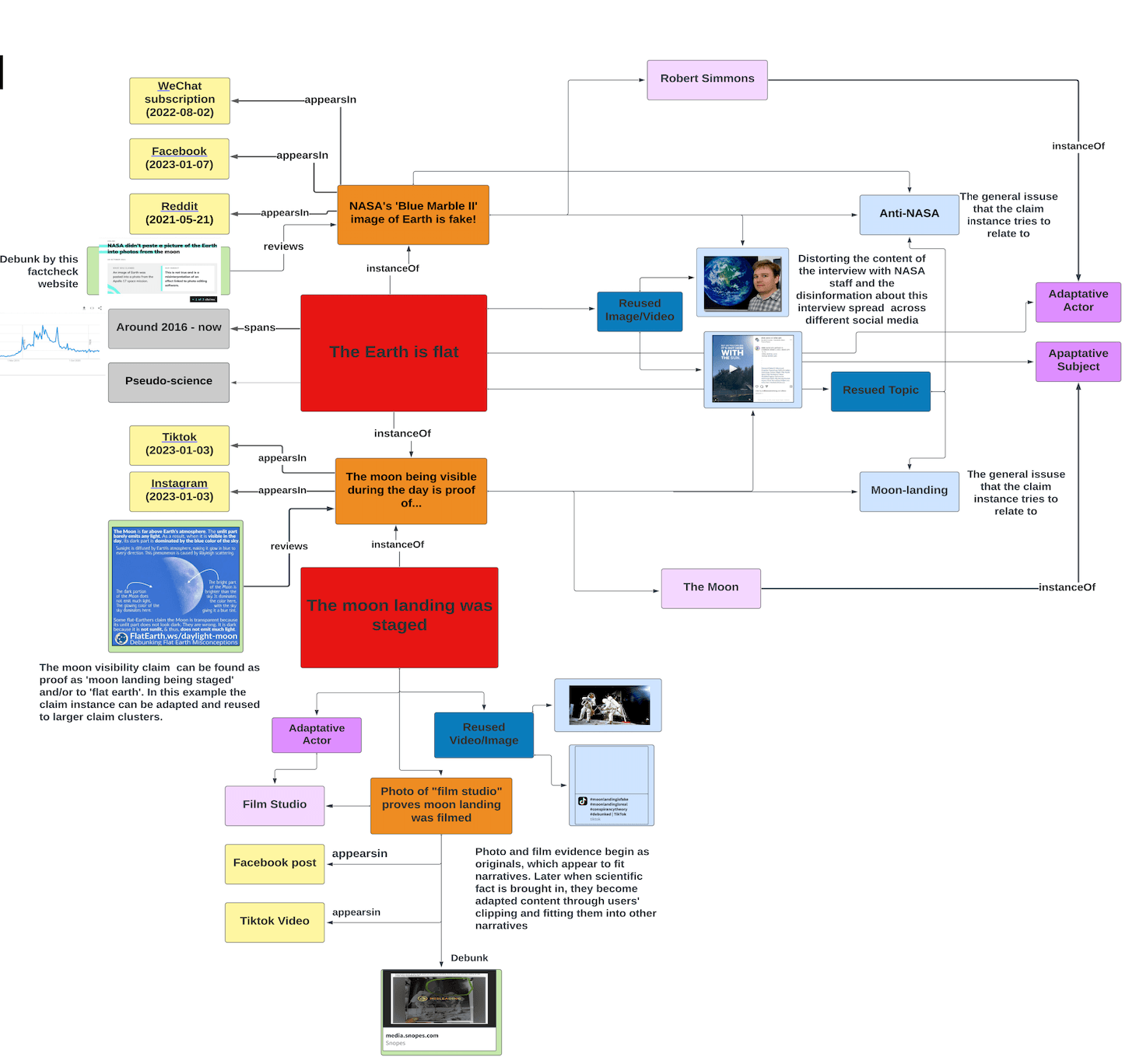
The starting point were appearances, which could be a post, an image, a news article, or another form of disinformation. These form a claim instance which is a collection of similar appearances linked to a debunking article that addresses the disinformation in the claim.
The claim instance, in turn, is an occurrence within the claim cluster, representing the generic overarching informative claim. The claim cluster also includes a time period in which the cluster exists, as well as a related topic.
Additionally, two types of content are developed from the claim cluster and correlate to the different claim instances. The first is reused content, which is information from the claim cluster that is used in multiple instances. Developing from the reused content are reused entities, which are specific examples of the reused content.
The second type of content is adaptive content, which is a change to the claim cluster that makes the claim instance unique. Adaptive entities are specific examples that follow the adaptive content. It is also possible for a claim instance to introduce another claim cluster which has different reused content from the first claim cluster.
Finally, at the closing event the participants presented a semantic model for describing disinformation spread with all its elements, and proposed a methodology for identifying and anticipating such disinformation spreading. Their solutions give answers to questions such as:
- How to model the spread of disinformation by identifying the reused content, the novel/adaptive content and the connection between various instances?
- How to identify examples of such spread and effectively communicate their nature to both investigative experts and regular people (separate questions)?
- What methodology (step-by-step) can be used by investigative experts in order to prevent the spread of disinformation?

The results
The data sprint was successful in producing several results with regards to internationally spread disinformation campaigns. These results include:
- Multiple examples of internationally spread disinformation campaigns, including the identification of reused content, novel/adaptive content, and connections between various instances.
- Guidelines on how to identify the spread of disinformation.
- Strategy for how investigative experts or institutions can effectively communicate about the spreading disinformation to regular people.
- Prevention methods when disinformation spread is successfully anticipated.
The findings from this project are expected to be beneficial for both investigators and other participants of the 2023 Winter School to gain insights into the dynamics of disinformation as well as to discover efficient methods of avoiding it.
Resources and supporting material
For more information see also the project wiki page on the DMI website.
The process and outcome of the work are also summarized in two posters (1, 2) and narrated videos (3, 4).
Author: Eneya Georgieva (Ontotext)
Facilitators: Andrey Tagarev, Eneya Georgieva (Ontotext)
Participants in the project: Alissa Drieduite, Andrea Moreno, Anna-Lisa Vuijk, Claire Verplanke, Dave Wismeijer, Ivar de Jong, Jady van Leusden, Kris Chu, Lorence Li, Luwe Groot, Min Young Park, Ruben den Harder, Sheung Yiu, Tamás Molnár, Wenhao Zhou, Yaiza Zarza-Franklin.
Editor: Jochen Spangenberg (DW)
