WHO IS BEHIND VERA.AI?
Meet: Stefanos-Iordanis Papadopoulos
With the interview format WHO IS BEHIND VERA.AI? we subsequently present the people who make up the project, their role within vera.ai as well as their views on challenges, trends and visions for the project's outcomes.
Who are you and what is your role within vera.ai?
I am Stefanos (Iordanis) Papadopoulos, leader of task 3.5 of the vera.ai project, focusing on de-contextualised multimedia content verification. I am an associate researcher at CERTH-ITI in Thessaloniki, Greece and a PhD candidate at the Department of Electrical and Computer Engineering, Aristotle University of Thessaloniki, Greece. You can find me on Google scholar and on LinkedIn.

What challenges and trends do you currently see regarding disinformation analysis and AI supported verification tools and services (and what will you do about it, if anything)?
One of the challenges that increasingly concerns me is the proliferation of misinformation through multiple forms of communication. While social media platforms have allowed for greater self-expression through texts, images, and videos, they have also made it easier for bad actors to spread false information that spans multiple modalities.
Unlike DeepFakes that require access to large generative deep learning models - which until recently weren’t as easily accessible - multimodal misinformation can be created with relative ease and without the need for advanced technical skills. One can easily take clips of videos out of their original context or obfuscate the origin of images in order to support their false narratives in the textual format. The challenge is multi-faceted, as we need to understand the origin, content, and context of visual modality that has been obfuscated, as well as its relation to the text.
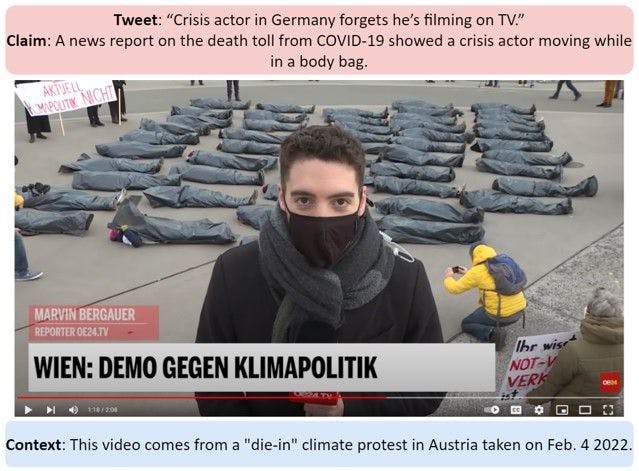
At the same time, I am really concerned about how fast misinformation can propagate as well as the scale of the problem. Given the sheer volume of information created each second, it is increasingly difficult for fact-checkers to keep up. For this reason, I believe that AI tools will be crucial in assisting the work of fact-checkers, for instance, by flagging and prioritizing content that is more likely to be misleading.
What is your 2025 vision of your contributions/outcomes within the scope of vera.ai?
My primary research focus is on the challenge of multimodal misinformation detection. It is common in deep learning research to aim for higher accuracy. Indeed it is crucial to have accurate models but it should not be our sole objective. We must also understand the potential biases and limitations of our models and try our best to minimize them.
In addition, providing fact-checkers with binary scores that merely identify whether or not a piece of content is misinformation has limited usefulness. Instead, our focus should be on providing predictions that are interpretable by humans. For example, an explainable model could analyze a Tweet and provide explanations such as "the image's original context has been fabricated," or "the image depicts an event that took place X years prior, not a current event". Such a model could also provide links to articles with high credibility that contradict a claim that is made. While developing explainable models is a challenging task, it can greatly benefit the work of fact-checkers by providing them with reasons and resources that can help them make the final call and speed up their workflow.
My aim for my research within vera.ai is to effectively address the aforementioned issues and generate high impact research that will benefit the research community in the field. I hope that our efforts will lead to more accurate, trustworthy and reliable services that can assist and even enhance the important work of fact-checkers.
What makes you happy/content?
Writing music with my bandmates, starting the day with a nutritious porridge bowl, walking in nature and seeing my deep learning models finally converge after endless hours (or even days!) of training.
Source links to in-text example picture: USA Today, Politifact
Author: Stefanos-Iordanis Papadopoulos (CERTH-ITI)
Editors: Anna Schild / Jochen Spangenberg (DW)
